
name: title class: title, middle
Emmanuel Bengio et al., arXiv:2106.04399
| .footer[alexhernandezgarcia.github.io | alex.hernandez-garcia@mila.quebec | @alexhdezgcia]  |
Generate diverse and high-reward samples $x$ from a large search space, given a reward $R(x)$ and a deterministic episodic environment where episodes terminate by generating a sample $x$.
–
Instead of sampling iteratively, as in Markov chain Monte-Carlo (MCMC methods), Flow Networks sample sequentially, like in episodic Reinforcement Learning (RL), by modelling $\pi(x) \propto R(x)$, that is a distribution proportional to the reward. Unlike RL methods, which generate a single highest-reward sequence, GFlowNet aims to sample multiple, diverse sample.
Directed acyclic graph (DAG) with sources and sinks.
.center[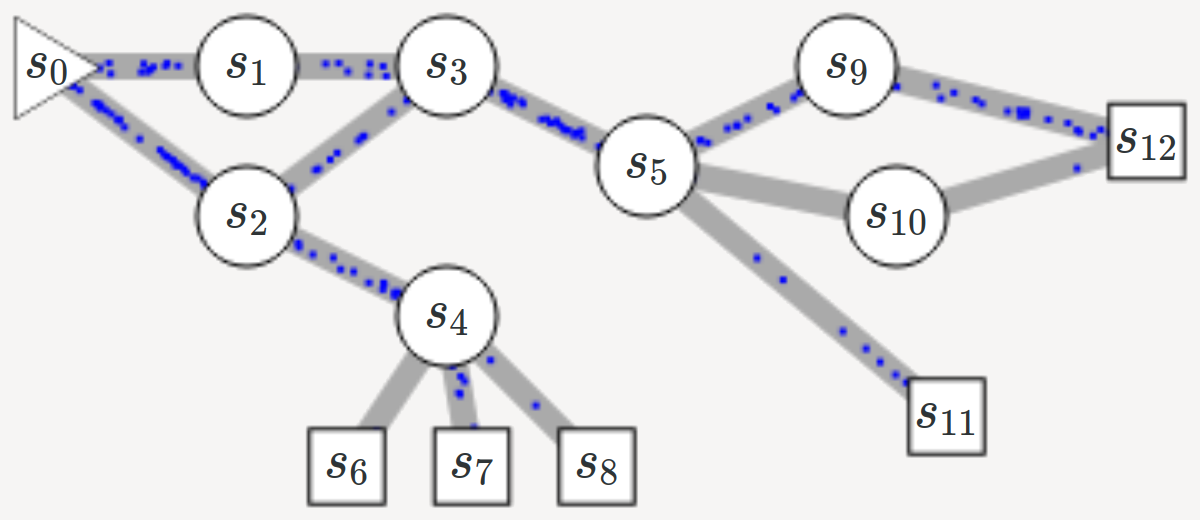 ]
]
.center[]
Given the structure of the graph and the reward of the sinks, we wish to calculate a_valid flow_ between nodes.
Multiple solutions are possible in general, which yields a generative model
Let
| $\pi(a | s) = \frac{Q(s,a)}{\sum_{a’} Q(s,a’)}$ |
Following policy $\pi$ from $s_0$ leads to terminal state $x$ with probability $R(x)$.
For every node $s’$:
–
The in-flow equals the out-flow, and the out-flow of the sink nodes is their associated reward $R(x) > 0$. Thus:
\[\sum^{s,a:T(s,a)=s'} Q(s,a) = R(s')+ \sum^{a' \in \mathcal{A}(s')} Q(s', a')\]–
A flow that satisfies the flow equations produces $\pi(x) = \frac{R(x)}{Z}$
The above equation can be seen as a recursive value function. We can approximate the flows such that the conditions are satisfied at convergence (as the Bellman conditions for temporal difference learning):
\[\tilde{\mathcal{L}}_{\theta}(\tau) = \sum^{s' \in \tau \neq s_0} \left( \sum^{s,a:T(s,a)=s'} Q(s,a;\theta) - R(s') - \sum^{a' \in \mathcal{A}(s')} Q(s',a';\theta)\right)^2\]–
For better numerical stability:
\[\footnotesize \tilde{\mathcal{L}}_{\theta,\epsilon}(\tau) = \sum^{s' \in \tau \neq s_0} \left( \log \left[ \epsilon + \sum^{s,a:T(s,a)=s'} \exp Q^{log}(s,a;\theta) \right] - \log \left[ \epsilon + R(s') - \sum^{a' \in \mathcal{A}(s')} \exp Q^{log}(s',a';\theta) \right] \right)^2\]Goal: generate a diverse set of small molecules that have high reward.